Abstract
Các ứng dụng cũ sử dụng mô hình đa lớp (multi-tier) dành cho các doanh nghiệp kinh doanh và được xây dựng dựa trên SOA (kiến trúc hướng dịch vụ) thường bị tấn công bởi các loại hình tấn công kiểu mới, mặc dù các ứng dụng này có thể chỉ được dùng trong nội bộ công ty.
Hiện nay trên thị trường có rất nhiều loại công cụ phân tích mã tĩnh (Static Analysis) giúp tìm ra các loại lỗ hổng (Vulnerability) low-level chẳng hạn như buffer overflow hoặc cross-site scripting (XSS). Tuy nhiên, vẫn còn thiếu các công cụ giúp đánh giá được kiến trúc bảo mật đã được cài đặt ở trong ứng dụng, đặc biệt là ở trong các ứng dụng cũ.
Trong bài báo này, các tác giả đề xuất ra một kỹ thuật giúp tự động trích xuất kiến trúc bảo mật đã được cài đặt ở trong mã nguồn của một ứng dụng Java. Sau đó, tiến hành threat modeling cho kiến trúc này để tìm ra các điểm yếu bảo mật cũng như các cách để giảm thiểu chúng. Cuối cùng, họ đánh giá và thảo luận dựa trên hai case studies: một ứng dụng e-goverment và một ứng dụng logistic.
Introduction
Khi áp dụng các công nghệ mới chẳng hạn như SOA vào các ứng dụng cũ thì lại gây ra nhiều thách thức về vấn đề bảo mật.
- Cộng đồng nghiên cứu và ngành công nghiệp giải quyết các vấn đề này bằng cách sử dụng kỹ thuật static analysis. Static analysis rất hiệu quả trong việc tìm ra các low-level bugs, nhưng kỹ thuật này vẫn không tìm ra được những lỗi bảo mật ở mức độ kiến trúc của phần mềm, chẳng hạn như lỗ hổng illogical role-based access control.
- Tồn tại nhiều phương pháp giúp đặc tả và validate kiến trúc bảo mật của ứng dụng theo một model nào đó, chẳng hạn như Model-Driven Security hoặc là UMLSec. Dù cho các cách tiếp cận này có thể được sử dụng rộng rãi hiện nay nhưng vẫn còn nhiều hệ thống cũ không triển khai cách tiếp cận này.
- Thêm vào đó, code sản sinh ra từ model có thể bị thay đổi tùy vào yêu cầu nào đó của khách hàng. Dẫn đến, kiến trúc phần mềm được đặc tả có thể sẽ không đồng bộ với kiến trúc phần mềm được cài đặt.
- Ngoài ra, quá trình threat modeling, mà theo như Microsoft mô tả, không giúp đánh giá kiến trúc bảo mật đã được cài đặt của phần mềm, mặc dù đây là một bước không thể thiếu trong quá trình phát triển phần mềm.
Cách tiếp cận của các tác giả là:
- Phân giải các ứng dụng business đa lớp thành nhiều components nhỏ lẻ khác nhau và tìm ra các luồng thông tin (information flows) giữa các component đó.
- Bằng cách này, chúng ta thu được một góc nhìn high-level của kiến trúc phần mềm đã được cài đặt trong ứng dụng. Kiến trúc này có thể dùng để làm thông tin đầu vào cho quá trình threat modeling.
- Hơn thế nữa, nếu có sẵn document của kiến trúc phần mềm, ta còn có thể áp dụng thêm kỹ thuật reflexion analysis.
Background
Static Code Analysis
Các tác giả sử dụng static code analysis để trích xuất kiến trúc bảo mật đã được cài đặt ở trong ứng dụng. Cụ thể, họ sử dụng công cụ Soot để phân tích bytecode của Java nhằm trích xuất một kiến trúc trừu tượng và độc lập nền tảng mà có thể được visualize với công cụ Bauhaus.
Threat Modeling
Threat Modeling là một kỹ thuật giúp kiểm tra kiến trúc của ứng dụng nhằm phát hiện ra các mối đe dọa có thể xảy ra.
- Cụ thể, hệ thống sẽ được phân giải ra làm nhiều processes, entities và dataflows. Bước này sẽ được documented bằng DFD.
- Sau đó, các chuyên gia sẽ liệt kê các mối đe dọa tồn tại trong hệ thống và phân loại chúng dựa trên STRIDE.
- Cuối cùng, các phương pháp giảm thiểu mối đe dọa sẽ được thiết kế và được gán cho từng mối đe dọa tương ứng, chẳng hạn như là authentication & authorization.
Annotated Dataflow Diagrams
Ngoài việc sử dụng DFD, chúng ta có thể sử dụng thêm DFD có chú thích (annotated DFD). Một annotated DFD sẽ có thêm các thông tin mà DFD truyền thống không có, chẳng hạn như ngôn ngữ lập trình được sử dụng, loại luồng dữ liệu, luồng dữ liệu có mã hóa hoặc có xác thực và có các dữ liệu nhạy cảm.
Kết hợp các thông tin này, nhà phân tích sẽ thực hiện quá trình threat modeling một cách hiệu quả hơn.
Interaction Points
Là những dataflows có dữ liệu đi vào hệ thống mà được cần phải được kiểm soát. Cụ thể, chúng là những dataflows mà attacker có thể tương tác nhằm tấn công vào hệ thống.
Bằng cách nhận diện các interaction points, chúng ta có thể giảm thiểu được phạm vi cần phân tích bảo mật ở trong DFD.
Our Approach
Lý do mà các tác giả tập trung vào việc trích xuất kiến trúc bảo mật đã được cài đặt của ứng dụng là vì hai lý do:
- Vì việc này làm đơn giản quá trình threat modeling.
- Vì kiến trúc được cài đặt đôi khi có thể sẽ khác so với kiến trúc được đặc tả.
Cách tiếp cận của các tác giả được chia ra làm các giai đoạn như sau:
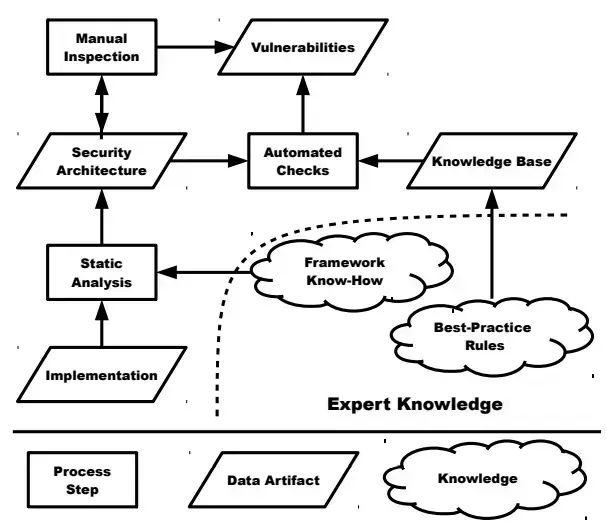
Từ phần mềm đã được xây dựng, họ sẽ sử dụng reverse engineering để trích xuất ra kiến trúc bảo mật. Kiến trúc này sẽ không phụ thuộc vào framework và được biểu diễn bằng DFD.
Sau đó, cải tiến DFD bằng cách thêm các annotations một cách tự động nhằm biểu diễn các biện pháp bảo mật đang có trong hệ thống. Các annotations này được thêm vào dựa trên implementation của phần mềm hoặc từ các files cấu hình.
Các tác giả xây dựng một nền tảng tri thức (knowlege base) chứa các mối đe dọa phổ biến và các best practices giúp giảm thiểu được các mối đe dọa đó. Họ kết nối kiến trúc bảo mật đã được trích xuất với các threat patterns đã biết ở trong knowledge base và phân loại các threats dựa trên STRIDE.
Ví dụ, một luồng dữ liệu có thể bị đánh dấu là truyền tải các thông tin nhạy cảm chẳng hạn như các certificates hoặc các thông tin của người dùng. Một rule 1 bên trong knowledge base sẽ giúp ánh xạ pattern này cho một threat và threat này sẽ được xếp vào phân loại “information disclosure” ở trong STRIDE.
Sau đó, duyệt qua DFD để tìm xem có tồn tại các mitigations cho các threats tương ứng hay không. Trong ví dụ trên, các mitigations có thể là mã hóa đường truyền hoặc mã hóa thông tin nhằm ngăn cản kẻ tấn công nghe lén các dữ liệu đang được truyền tải.
Cũng có thể tìm ra các threats một cách thủ công mà không cần dùng đến knowledge base.
Ngoài ra, có thể thêm vào kiến trúc bảo mật các thông tin phụ trợ mà không có trong implementation của ứng dụng mà đến từ môi trường của ứng dụng, chẳng hạn như tường lửa.
Security Architecture
Để xây dựng model cho kiến trúc bảo mật, các tác giả sử dụng kết hợp các DFDs được định nghĩa bởi Swiderski, Snyderand và Dhillon.
Minh họa cho meta-model của DFD:
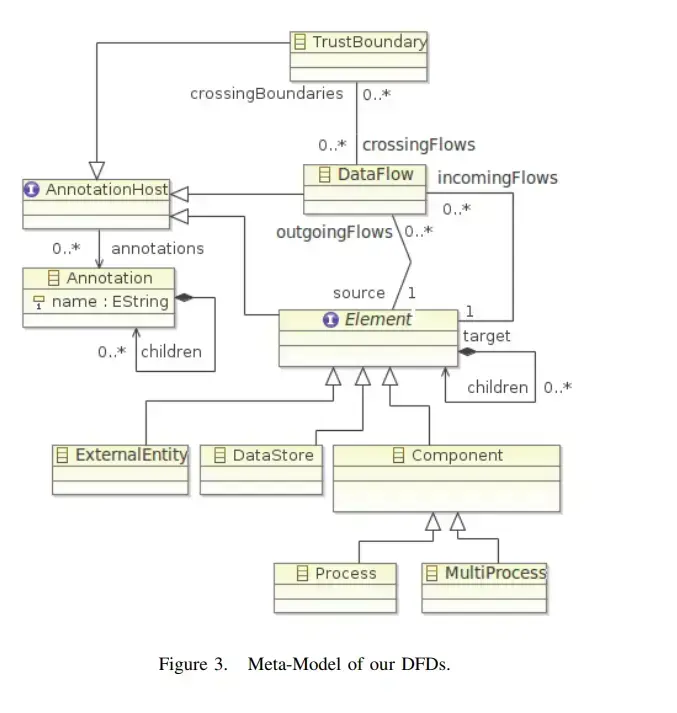
Model trên bao gồm các elements có thứ bậc, trust boundaries và dataflows. Mỗi elements có thể có tùy ý các annotations khác nhau, và các annotations này cũng có thể chứa các annotations khác.
Bằng cách này, các tác giả có thể biểu diễn được các threat patterns cũng như các mitigations tương ứng ở abstract level và liên kết chúng với các concrete concepts ở mức low level.
Ví dụ với annotation “Encryption”, biểu trưng cho luồng dữ liệu đã được mã hóa. Annotation này có thể được tách ra hai concrete concepts là mã hóa đường truyền (transport encryption) và mã hóa thông điệp (message encryption).
Static Analysis
Việc dịch ngược kiến trúc bảo mật của một hệ thống có một số vấn đề:
- Cần phải biết và hỗ trợ tất cả các frameworks được sử dụng ở trong ứng dụng bởi vì tùy từng framework mà chúng ta sẽ sử dụng các kỹ thuật khác nhau để thu thập thông tin từ mã nguồn.
- Cần phải tìm ra cách ánh xạ giữa các artifacts (các sản phẩm của quá trình phát triển phần mềm, có thể là document, diagram, mã nguồn, test cases, etc) với kiến trúc trừu tượng đã được mô tả.
Các tác giả áp dụng kỹ thuật static analysis thông qua năm bước liên tiếp nhau như sau:
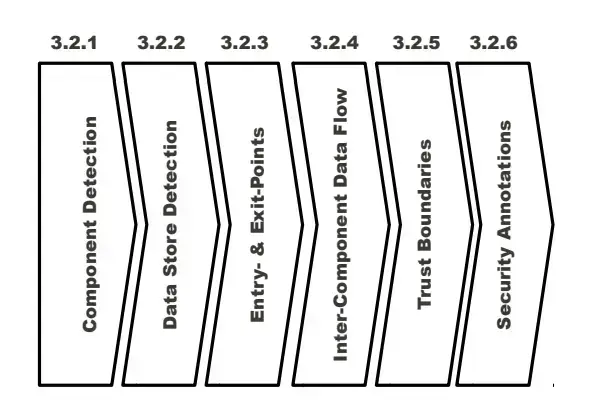
Năm bước này có thể áp dụng cho các miền ứng dụng khác, chẳng hạn như các ứng dụng Android.
Cụ thể:
- Chia hệ thống ra làm nhiều components, chẳng hạn như là các processes, web services, enterprise beans (là các component có trong JEE) và các dynamic web pages (hay còn gọi là các servlets). Mỗi component ở trên sẽ được chuyển hóa thành một phần tử ở trong DFD.
- Duyệt qua từng components để tìm ra các entry và exit points của dữ liệu và luồng điều khiển (control flow).
- Kế đến, kết nối các entry và exit points để tìm ra các dataflow giữa các component với nhau.
- Dựa trên các thông tin thu được từ các component khác nhau, tạo ra các trust boundaries.
Chú ý: việc trích xuất các external entities từ trong mã nguồn gần như là không thể. Do vậy, hiện tại các tác giả đang tạo ra một external user nhân tạo mà có tương tác với tất cả các public interfaces.
Component Detection
Ở bước này, các artifacts sẽ được duyệt qua để tìm ra các “dấu hiệu” của các processes. Các dấu hiệu này dựa trên các loại frameworks được sử dụng trong ứng dụng và có thể được tìm thấy ở các files cấu hình được deployed cùng với compiled program.
Các processes sau đó cũng sẽ được duyệt qua để tìm ra các substructure, chẳng hạn như web components, enterprise beans hoặc web services.
Mỗi component tìm được sẽ tương ứng với một phần tử ở trong DFD và có thể được mở rộng ra bởi các component con của nó.
Data Store Detection
Để phát hiện ra các data stores, chúng ta cần phải xem xét mã nguồn cũng như là các files cấu hình. Bên trong các artifacts đó, có thể tìm thấy được những kết nối đến những persistant objects, chẳng hạn như các files hoặc các databases.
Data store detection gần như là gắn liền với dataflow detection bởi vì việc sử dụng data store luôn tương ứng với một dataflow giữa component với data store.
Entry and Exit Points Detection
Entry và exit points là các phương thức và các lời gọi phương thức của chương trình mà thực hiện các công việc chẳng hạn như là giao tiếp giữa các component, tương tác người dùng hoặc là truy cập tập tin.
Để tìm ra các điểm này, cần phải tìm kiếm trong các component các điểm mà luồng dữ liệu và luồng điều khiển đi vào hoặc đi ra.
Một ví dụ của entry point là các phương thức được gọi thực thi bởi một framework nào đó, chẳng hạn như là các phương thức liên quan đến web request. Các phương thức này có thể được gọi từ xa và bị tấn công.
Do ta không thể phân biệt tất cả các external entities một cách chính xác nên cần tạo ra một external entity nhân tạo mà có kết nối đến từng entry point khả dụng của các component.
Entry và exit points có thể phân thành hai loại là tổng quát và dựa trên framework cụ thể.
- Loại thứ nhất gắn liền với giao tiếp thông qua mạng và gọi phương thức từ xa (Remote Method Invocation).
- Loại thứ hai bao gồm các phương thức web service, Enterprise Session Beans và các tập tin JSP (JavaServer Pages).
Extract Inter-component Dataflow
Tại thời điểm này, các phần tử ở trong DFD vẫn chưa được liên kết với nhau. Do đó, ta sẽ cố kết nối những entry và exit points của những components khác nhau lại với nhau nếu có thể. Nói cách khác, chúng ta cần phải trích xuất các dataflow vốn là rất là phức tạp trong các hệ thống phân tán khi có vài processes liên lạc với nhau.
Để giải quyết vấn đề này, cần sử dụng các loại static analysis khác nhau đối với từng loại framework cụ thể nhằm tìm ra các dataflows có trong hệ thống.
Trust Boundary Derivation
Trust boundary có thể có nhiều nghĩa và các hàm ý khác nhau. Do đó, việc trích xuất tự động là khá khó khăn. Hai ý nghĩa phổ biến của trust boundary là:
- Hai processes cần phụ thuộc lẫn nhau để có thể hoạt động.
- Tất cả các processes ở trong một trust boundary cùng chạy trên một máy tính tin cậy và do đó không cần sử dụng mã hóa hoặc tiến hành kiểm tra access control.
Một vài trong số các trust boundaries có thể được trích xuất từ các thông tin liên quan đến deploy đi kèm với ứng dụng. Tuy nhiên, vẫn là khá khó khăn để tìm ra được các trust boundaries thực sự của ứng dụng. Do đó, cần phải sửa lại các trust boundaries một cách thủ công sau khi thực hiện bước trích xuất.
Security Annotations
Để có thể biểu diễn các quy luật bảo mật và các chức năng bảo mật cho từng loại framework, các tác giả tạo ra một tập các ký hiệu bảo mật và có thể mở rộng trong quá trình trích xuất tự động cũng như là quá trình trích xuất thủ công.
Bằng cách này, người dùng có thể thêm vào các thông tin phụ trợ trong bước refinement một cách thủ công.
Supported Framework
Các frameworks hỗ trợ và các DFD đã được tạo tương ứng.
Java Applications
Là các ứng dụng Java bình thường với hàm main có dạng: public static void main (String [] args). Để nhận diện được những phương thức như này, các tác giả sẽ duyệt qua thông tin về kiểu dữ liệu cho tất cả các classes có trong chương trình. Mỗi hàm main tìm được sẽ tương ứng với một process node.
Hiện tại, các tác giả không tiếp tục chia nhỏ các process này ra nữa, chẳng hạn chia ra thành các threads đơn lẻ.
Tiếp theo, dùng Soot để tạo ra một context sensitive hoặc context insensitive call graph cho từng hàm main nhằm nhận diện phân đoạn mã nguồn được dùng để triển khai ứng dụng.
Java Enterprise Edition
Là các ứng dụng dành cho các doanh nghiệp, được triển khai trên nền tảng JEE. Các ứng dụng thuộc loại này sẽ được phân thành nhiều modules, mỗi modules sẽ thực hiện một tác vụ cụ thể. Các modules bao gồm:
- Web frontends
- Fat clients (chủ yếu xử lý và hiển thị thông tin ở phía client thay vì server)
- Business logic
- Các thư viện
Tất cả các modules này sẽ được liệt kê trong các files XML cụ thể, còn được gọi là các deployment descriptors.
Mỗi ứng dụng enterprise sẽ có một process element tương ứng. Element này có thể có các sub-elements đại diện cho từng modules đã được định nghĩa ở trong ứng dụng.
Ở trong business logic module, các lập trình viên sử dụng EJB để cung cấp các xử lý nghiệp vụ đến các lớp của giao diện người dùng. Tùy thuộc vào phiên bản của JEE, enterprise java beans sẽ được khai báo cùng với sự hỗ trợ của các files cấu hình hoặc với sự hỗ trợ của các annotations của Java.
Trong một số trường hợp, các EJBs có thể được truy cập từ các processes khác. Đó là lý do mà ta cần phải thêm vào DFD một dataflow từ externel user vào business logic module.
Kể từ phiên bản 1.4 theo đặc tả của JEE, các entity beans sẽ chịu trách nhiệm duy trì kết nối đến database. Do đó, nếu tìm thấy các entity beans ở trong code, chúng ta cần đọc các files cấu hình có liên quan để tìm ra database được sử dụng và tạo ra một data store element tương ứng ở trong DFD.
Đối với web modules, các tác giả tìm kiếm các Servlets, là các classes Java giúp sản sinh ra các nội dung của trang web. Bởi vì các servlets được sử dụng thông qua HTTP, ta có thể xem các web modules như là các entry points của hệ thống. Do đó, ta cần thêm thông tin này vào DFD.
Bên cạnh các thông tin liên quan đến cấu trúc của chương trình, JEE còn cung cấp các dịch vụ liên quan đến bảo mật. Các container-based authentication giúp đảm bảo rằng mỗi client của một web module luôn được xác thực trước khi nhận được bất kỳ kết quả trả về nào. Hơn thế nữa, container-based authorization cũng được hỗ trợ (dựa trên vai trò của client mà cung cấp access control phù hợp) và đem lại hai thông tin hữu ích:
- Nó cho biết authorization được sử dụng ở trong ứng dụng.
- Có thể giúp nhận biết được các external entities.
Ngoài ra, JEE còn hỗ trợ mã hóa dữ liệu khi gửi cho hosts khác.
Web Services
Được cài đặt thông qua Java API hoặc XML web services, là các thành phần có thể được gọi từ xa. Mỗi web service sẽ tương ứng với một process element ở trong DFD.
Bằng cách sử dụng các annotations mô tả về interface của các web services, chúng ta có thể tìm ra các lời gọi thực hiện phương thức giữa các clients và web service. Chúng ta có thể thêm vào DFD các cạnh dataflow dựa trên các lời gọi đó.
Ngoài ra, các policies enforce những biện pháp bảo mật ở message level, chẳng hạn như mã hóa message, message signing hoặc timestamp, cũng sẽ được thêm vào DFD dưới dạng các annotations.
File Access
Bằng cách tìm trong code những nơi có sử dụng các classes của package java.io thông qua Soot, ta có thể trích xuất ra tên của tất cả các file được truy cập đến. Để làm được điều này, ta cần phải tiến hành các kỹ thuật chẳng hạn như là flow sensitive, inter-procedural constant propagation và points-to analysis để tìm ra các tên files.
Tuy nhiên, không phải tất cả các tên files đều có thể được trích xuất thông qua static analysis, chẳng hạn như là các tên file mà do người dùng nhập vào, dẫn đến sự tồn tại của các files không có tên.
Đối với từng file đã được nhận diện, một data store tương ứng sẽ được tạo ra ở trong DFD (chỉ áp dụng đối với các files có tên). Đồng thời, một dataflow giữa component truy xuất đến file và data store cũng cần được thêm vào DFD.
Java Persistance API
Dựa trên các annotations của Java và file cấu hình persistance.xml, chúng ta tìm ra các đoạn code có sử dụng Java Persistance API (một chuẩn API của Java nhằm duy trì các đối tượng kết nối đến các cơ sở dữ liệu SQL). Mỗi database được tìm thấy sẽ tương ứng với một data store và sẽ có một dataflow được thêm vào DFD tùy theo cách thức sử dụng database đó.
Java Messaging Service
Khi sử dụng Java Message Service, các thông điệp sẽ được gửi đi thông qua một tên topic2 hoặc một tên queue2 cụ thể nào đó mà client cần phải biết. Chúng ta sử dụng kỹ thuật inter-procedural constant propagation để tìm ra các topics mà chương trình có kết nối đến.
Một cách tổng quát, điều này là không khả thi do tên của các topics có thể được tạo ra lúc run time. Tuy nhiên, đây không phải là một trường hợp mà các tác giả sẽ xem xét đến trong các case studies của họ.
Sau khi có được tên của các topics, cần phải trích xuất các thao tác được thực hiện trên các topics đó nhằm phân biệt đâu là thao tác gửi và đâu là thao tác nhận thông điệp.
Bằng cách này, ta có thể tìm được các dataflows giữa các applications có sử dụng JMS.
Best Practices
Để tạo ra knowledge base có chứa tất cả các threats phổ biến cũng như các mitigations khả thi, chúng ta cần sử dụng CWE, là một danh sách có một số các loại vấn đề bảo mật, hậu quả cũng như các cách khắc phục chúng.
Nếu có thể, ta nên chuyển tất cả các threats có trong CWE sang dạng DFD và chuyển các mitigations sang dạng annotation-based mitigations. Trong quá trình này, ta cần tạo ra một tập các annotations cho các thuộc tính bảo mật của các elements có trong DFD cũng như là các mitigations.
Đồng thời, cần tạo ra các rules dùng để dẫn xuất các mitigations dựa trên các thuộc tính bảo mật của các elements. Các rules này sẽ được viết bằng OCL, là một ngôn ngữ giúp thể hiện các ràng buộc cho các model instance ở trong metamodel.
Ví dụ của một rule:
context DataFlow inv EncryptedChannel :
self.annotations ➔
exists (d | d.name = 'Data.IsConfidential')
implies self . annotations ➔
exists (d | d.name = 'DataFlow.IsEncrypted')Rule này kiểm tra xem nếu dataflow có bảo mật hay không (được biểu diễn bằng annotation Data.IsConfidential), nếu có thì phải tồn tại annotation DataFlow.IsEncrypted.
Với sự hỗ trợ của một rule đơn giản như thế, ta có test được điểm yếu CWE-5 J2EE Misconfiguration: Data Transmission Without Encryption của CWE.
Implementation Aspects
Các tác giả triển khai ý tưởng của họ bằng nhiều công cụ khác nhau: Bauhaus, Eclipse và Soot. Trong đó, Bauhaus cung cấp khả năng dịch ngược, Soot giúp thực hiện static analysis và Eclipse thì hỗ trợ framework dùng để xây dựng DFD.
Case Studies
Chúng ta xem xét hai case studies về các ứng dụng thương mại để trả lời một tập các câu hỏi cho sẵn, cụ thể là:
- Q1: DFD được trích xuất có tương tự với cái mà được tạo bởi các security-aware developer (các developer có nhận thức về các vấn đề bảo mật) hay không?
- Q2: Phần nào của kiến trúc có thể được trích xuất tự động?
- Q3: Liệu có thể tìm ra các vấn đề bảo mật dựa trên cách tiếp cận đã đề xuất hay không?
Case Study Setup
Case study đầu tiên thuộc lĩnh vực e-government và dựa trên công nghệ web service. Nó được triển khai bằng kiến trúc SOA và bao gồm nhiều web services, các ứng dụng JEE và các ứng dụng Java thông thường.
Các tác giả sẽ tập trung chủ yếu vào một hệ thống con giúp tạo ra chữ ký điện tử cho các tài liệu bất kỳ. Cụ thể, ứng dụng này sẽ cung cấp một cơ chế ký chữ ký điện tử cho các tài liệu tương tự nhau với cùng một khóa tại cùng một thời điểm.
Ứng dụng này có chứa các loại components đã nêu ở trước và sử dụng nhiều loại giao tiếp khác nhau giữa các component. Vì lý do đó, bảo mật là một khía cạnh cần được quan tâm.
Case study thứ hai là một ứng dụng thương mại của doanh nghiệp thuộc lĩnh vực logistics. Ứng dụng này giúp các công ty khai báo hàng hóa xuất nhập khẩu và được sử dụng bởi hàng trăm khách hàng mỗi ngày. Ứng dụng này được xây dựng dựa trên JEE phiên bản 1.4, mã nguồn của nó có hơn 600 ngàn dòng cũng như là có hơn 1000 files JavaServer Pages.
Ứng dụng này được cung cấp cho người dùng dưới dạng SaaS (Software as a Service) nên cần phải đảm bảo các yêu cầu bảo mật chẳng hạn như ẩn giấu thông tin (confidentiality) và chống thoái thác trách nhiệm (non-repudiation).
Results
Sau khi tự động trích xuất kiến trúc cho cả hai case studies và sử dụng knowledge base để tự động nhận diện các threats cũng như là các mitigations tương ứng thì các tác giả tiến hành phân tích các kết quả cũng như thảo luận với các chuyên gia để trả lời 3 câu hỏi đã được đề cập ở trên.
E-government Application
DFD được trích xuất đối với ứng dụng đầu tiên chỉ cần thêm vào vài chi tiết nhỏ là đã đủ thỏa mãn nhu cầu của các chuyên gia bảo mật. Cụ thể, DFD của kiến trúc được trích xuất sẽ có dạng sau đây (tên của các phần tử đã được thay đổi nhằm bảo đảm an toàn thông tin):
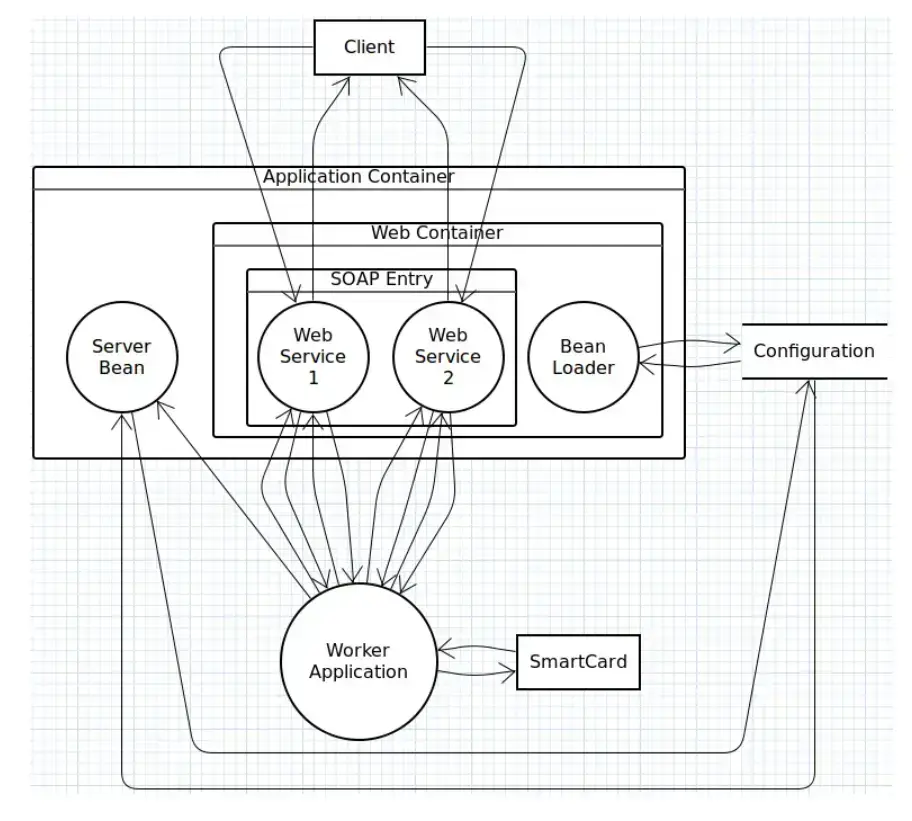
Sau quá trình trích xuất, có tổng cộng 9 top-level processes cũng như là các sub-processes giúp cung cấp những chức năng cụ thể đã được tìm thấy ở trong ứng dụng. Bốn trong số các top-level components không có trong sơ đồ trên vì chúng liên quan đến các chương trình kiểm thử ở bên thứ ba và không liên quan.
Bên cạnh kiến trúc của ứng dụng, các tác giả cũng đã nhận diện được các biện pháp bảo mật được triển khai ở hệ thống chẳng hạn như xác thực người dùng dựa trên chứng chỉ (authentication based on client-certificates) hoặc WS-security (Web Service Security) giúp bảo mật ở message level và
Tuy nhiên, họ không thể tự động nhận diện được các lỗ hổng trong kiến trúc đã được trích xuất bởi vì tất cả các threats được tìm thấy đều đã được mitigated. Đây là điều không quá ngạc nhiên đới với một ứng dụng đã được đánh giá nhiều lần dựa trên Common Criteria (CC), một chuẩn đánh giá bảo mật cho các sản phẩm IT.
Tồn tại một số sự khác biệt giữa DFD được tạo thủ công và cái được tạo tự động. Cụ thể, các tác giả tìm thấy vài processes mà theo các chuyên gia bảo mật thì không thuộc về hệ thống (có thể là các thư viện của các bên thứ ba). Tuy nhiên, những processes này có thể được chạy bởi các nhân viên sản xuất phần mềm và có tương tác với hệ thống.
Ngoài ra, kỹ thuật của các tác giả không thể tìm thấy các trust boundaries được thêm vào DFD một cách thủ công.
Sau khi có được kiến trúc của hệ thống, các tác giả đã nhận diện được một lỗ hổng authorization cho phép tất cả các khách hàng đã xác thực sử dụng tất cả các thẻ thông minh để ký bất kỳ tài liệu nào.
Custom Application
Với case study thứ hai, các tác giả trích xuất được kiến trúc có ba top-level processes: có một external entity - là web browser - giao tiếp với application container sử dụng HTTP. Còn application container thì trao đổi dữ liệu với data store, cụ thể là SQL database.
Kiến trúc tổng quan có dạng như sau:
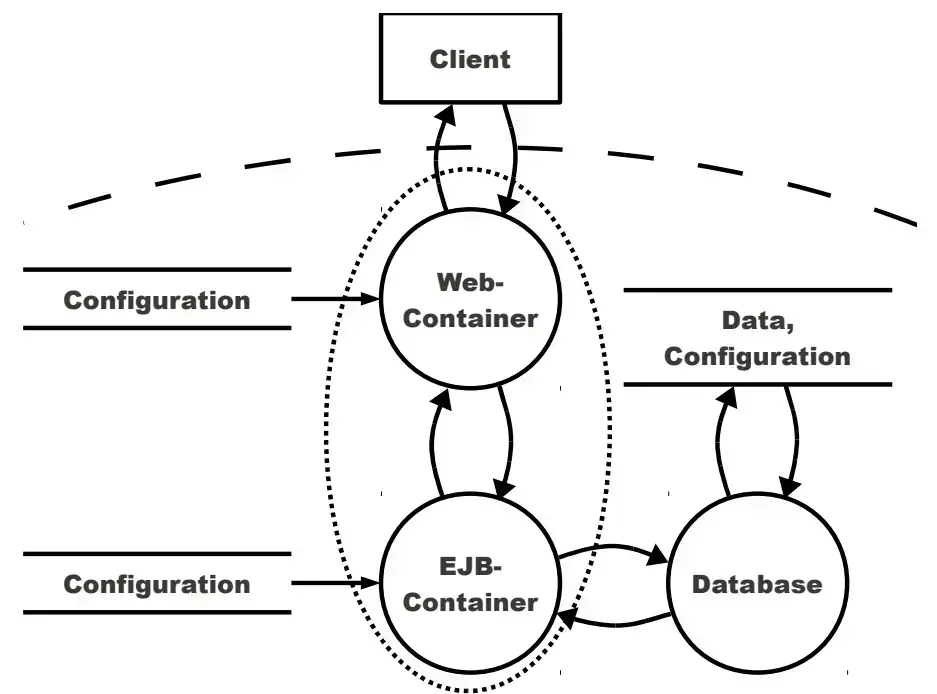
Dựa trên các thông tin deploy, application container process sẽ được chia thành hai phần là web frontend và xử lý logic nghiệp vụ.
Tồn tại một dataflow giữa một external entity (browser của client) có giao tiếp với web frontend. Web frontend cũng có giao tiếp với business logic cũng như là database. Bản thân business logic cũng có liên kết với database.
Các tác giả tìm thấy các biện pháp bảo mật được sử dụng ở trong phần mềm, chẳng hạn như chức năng xác thực, và họ thêm nó vào DFD. Bằng cách xem xét DFD đầu ra và sử dụng knowledge base, họ tìm thấy vài lỗ hổng. Hai trong số đó sẽ được trình bày ngay sau đây:
Thông qua kiến trúc được trích xuất, phát hiện được rằng dataflow giữa client và web frontend truyền tải các thông tin xác thực bằng giao thức HTTP. Dựa trên điều này, họ thêm threat “Một attacker có thể bắt được các thông tin xác thực bằng cách nghe lén đường mạng” vào phân loại Spoofing của STRIDE.
Hiển nhiên, mitigation cho threat này sẽ là mã hóa thông điệp hoặc là mã hóa đường truyền. Tuy nhiên, kỹ thuật của họ không gợi ý rằng cần phải sử dụng mitigation này. Thông qua kiểm tra mã nguồn, họ phát hiện được rằng các lập trình viên đã cấu hình sử dụng TLS không đúng. Cụ thể, vấn đề này tương ứng với CWE-5 J2EE Misconfiguration.
Ngoài ra, các tác giả cũng refine lại external entities sau khi trích xuất bởi vì các developers nói với họ là có hai loại người dùng, các người dùng thông thường và các admin. Dẫn đến, threat tương ứng sẽ là “Một client có thể bypass phân quyền bằng cách giao tiếp trực tiếp với server” (CWE-602), thuộc phân loại Privilege Escalation. Để mitigate threat này, server cần tự thực hiện phân quyền.
Discussion and Threats to Validity
Các tác giả đã trích xuất được hai DFDs một cách tự động cho các hệ thống thương mại và đã thảo luận hai lỗ hổng bảo mật cũng như là threat và mitigation tương ứng với hai lỗ hổng này. Tất cả các thông tin này đều được trích xuất từ mã nguồn của các ứng dụng JEE. DFD được trích xuất giúp chúng ta hiểu được kết cấu, kiến trúc của hệ thống và các chức năng bảo mật của phần mềm mặc dù chúng ta không biết các chi tiết bên trong chương trình.
Như vậy, DFD được trích xuất sẽ có dạng tương tự với DFD được xây dựng bởi các chuyên gia bảo mật (Q1). Từ DFD này, có thể trích xuất các processes, data stores cũng như là các kênh truyền dữ liệu. Tuy nhiên, các tác giả không thể nhận diện được các trust boundaries cũng như là các external entities một cách tự động và chính xác (Q2), điều này là không quá ngạc nhiên vì các external entities không nằm trong phạm vi của quá trình phân tích. Ở trong case study thứ hai, các tác giả đã có thể nhận diện và xử lý được các lỗ hổng dựa trên knowledge base đã được xây dựng (Q3).
Vẫn tồn tại một số hạn chế của cách tiếp cận này.
- Đầu tiên, static analysis thường có xu hướng không chính xác khi dựa trên các giả định bi quan (giả định xấu nhất) mà nó phải thực hiện để đảm bảo tính chính xác của quá trình phân tích. Các giả định này có thể làm cho kết quả phân tích chứa những vấn đề không thực sự tồn tại (ta gọi hiện tượng này là dương tính giả - false positive3).
- Để giảm thiểu số lượng dương tính giả, các tác giả sử dụng thêm các thông tin liên quan đến quá trình development và configuration. Nếu thay đổi các thông tin này trong quá trình phân tích thì kết quả phân tích sẽ không có giá trị.
- Tùy thuộc vào nhu cầu về độ chính xác, phân tích tĩnh thì có thể phải sử dụng rất nhiều bộ nhớ và thời gian. Tài nguyên tiêu thụ tăng tỉ lệ thuận với số frameworks được sử dụng ở trong ứng dụng.
- Thứ hai, cách tiếp cận của các tác giả chỉ hỗ trợ một số frameworks nhất định. Do đó, để có thể sử dụng rộng rãi, đòi hỏi cần phải có một lượng lớn các implementation và các công việc kỹ thuật.
- Thứ ba, việc nhận dạng được các loại người dùng, các biện pháp bảo mật đang tồn tại ở trong hệ thống (chẳng hạn như các tường lửa) và độ phân phối của phần mềm cho các máy khác nhau là khó hoặc thậm chí không thể thực hiện. Tuy nhiên, khả năng thêm các annotations vào DFD cũng cho phép bổ sung các thông tin trên vào quá trình phân tích.
Tại thời điểm hiện tại, số lượng các lỗ hổng liên quan đến kiến trúc có trong knowledge base là hạn chế vì chỉ được trích xuất từ CWE. Ngoài ra, không phải lỗ hổng nào cũng có thể được nhận dạng và mitigate. Đặc biệt là các lỗ hổng liên quan đến DoS bởi vì hệ thống cần phải xử lý tất cả các requests từ hacker thì mới biết được là request có hợp lệ hay không.
Một khía cạnh khác là áp dụng cách tiếp cận của các tác giả trong quá trình đánh giá phần mềm theo CC (Common Criteria). Các cuộc thảo luận với các CC evaluators cho thấy rằng họ thường có rất ít thời gian và chuyên môn để hiểu kiến trúc bảo mật đã được implement nên họ bắt buộc phải tin tưởng vào những tuyên bố về bảo mật của các vendors. Cách tiếp cận của các tác giả giúp chỉ ra những security-critical regions ở trong code, từ đó làm đơn giản đi quá trình nhận diện các architectural weeknesses của evaluators.
Related Works
Lĩnh vực static analysis đã rất phát triển trong những năm vừa qua. Các nghiên cứu quan trọng có thể kể đến như MOPS, Eau Claire và LAPSE. MOPS sử dụng kỹ thuật temporal logic và model checking để tìm ra các loại vấn đề chẳng hạn như race conditions ở trong các chương trình C. Eau Claire có thể phát hiện các vấn đề bảo mật tổng quát chẳng hạn như là buffer overflow hoặc race conditions dựa trên static type checking. Tất cả các cách tiếp cận này đều tập trung vào tìm các loại bug bảo mật low-level. Trong khi đó, cách tiếp cận của các tác giả là bổ sung cho các loại trên vì họ phân tích implemented architecture.
Ngoài ra, có một số nghiên cứu về việc phát hiện các kênh truyền bí mật của ứng dụng. Tuy nhiên, cách tiếp cận này không thể áp dụng cho các mã nguồn cũ.
Một cách tiếp cận khác là sử dụng model-driven development thông qua hai ngôn ngữ là SecureUML và UMLSec. Tuy nhiên, hai ngôn ngữ này chỉ xem xét chức năng bảo mật của hệ thống mà không xét ở góc nhìn của các attackers. Thêm vào đó, chúng cũng không thể áp dụng cho các mã nguồn cũ.
Còn có cách tiếp cận SiSOA dựa trên kỹ thuật phân tích cú pháp của mã nguồn nhằm trích xuất các artifacts liên quan đến bảo mật của các ứng dụng được xây dựng theo kiến trúc SOA và sử dụng Apache Tusnacy. Cách tiếp cận này chỉ giới hạn cho các ứng dụng có sử dụng Tuscany.
Thêm một cách tiếp cận nữa là sử dụng Ownership Object-Graphs (OOG), biểu diễn kiến trúc phân cấp của object trong quá trình runtime. Khi so sánh OOG với DFD, ta có thể tìm ra được các dataflow không được phép có ở trong ứng dụng. Cách tiếp cận này đang được thí nghiệm trên các hệ thống nhỏ và không phân tán.
Conclusion and Outlook
Conclusion
Trong bài báo này, các tác giả đã mô tả một phương pháp giúp trích xuất kiến trúc bảo mật từ mã nguồn của một ứng dụng Java dành cho business với sự hỗ trợ của kỹ thuật static analysis.
Dựa trên kiến trúc này, có thể tự động hoàn thành việc phân tích để tìm ra các điểm yếu của kiến trúc bằng cách sử dụng threat modelling. Danh sách các lỗ hổng ở trong threat model được dựa trên danh sách các điểm yếu thường gặp (CWE) và chúng có bao gồm các mitigations.
Để dễ xem xét và làm gọn kiến trúc, các tác giả cũng đã xây dựng một plugin giúp minh họa dùng cho Eclipse.
Cuối cùng, họ đã đánh giá cách tiếp cận được nêu với sự hỗ trợ của hai case studies trong thế giới thực.
Outlook
Trong tương lai, các tác giả có thể mở rộng framework ra để hỗ trợ nhiều nền tảng khác hoặc các frameworks khác, chẳng hạn như Android. Kèm theo đó, họ còn cần mở rộng knowledge base để có thể hỗ trợ cho nhiều loại threats cũng như các mitigations cho các loại threats đó. Đồng thời, sẽ rất hữu ích nếu có thể áp dụng các phương pháp của trí tuệ nhân tạo để tìm ra một cách biểu diễn mới của knowledge base dưới dạng các rules.
Footnotes
-
Các rules được liệt kê trong phần Best practices. ↩
-
Xem thêm Java Message Service. ↩ ↩2
-
Xem thêm Static Analysis for Security ↩