Introduction
Những kỹ thuật phân tích bảo mật nhằm cải thiện CIA của phần mềm đều dựa trên các attack surfaces một cách trực tiếp hoặc gián tiếp. Do đó, quá trình phân tích attack surface đóng vai trò rất quan trọng trong các phương pháp phân tích rủi ro bảo mật, phát hiện lỗ hổng và kiểm thử phần mềm.
Những vấn đề của các nghiên cứu trước đây:
- Chỉ tập trung vào việc phân tích các attack surface hơn là nhận diện các attack surface.
- Có một vài nghiên cứu xây dựng khái niệm về attack surface, xem xét entry, exit points, các kênh truyền, etc như là các attack surfaces. Tuy nhiên, những nghiên cứu này chỉ tập trung phân tích các attack surfaces của OS và web app nên nó có phạm vi rất giới hạn và phụ thuộc vào các ví dụ cụ thể.
- Không có nghiên cứu nào trước đó sử dụng một cách tiếp cận dễ hiểu để phân biệt và nhận diện các attack surfaces của các hệ thống phần mềm.
Cách tiếp cận của các tác giả:
- Grounded theory (GT) là một cách tiếp cận định tính giúp trích xuất các lý thuyết từ dữ liệu không có cấu trúc và dẫn đến những khám phá mới được hỗ trợ trực tiếp bởi các bằng chứng kinh nghiệm.
- Các tác giả sử dụng GT để nhận diện các high-level concepts liên quan đến các attack surfaces của hệ thống phần mềm và sử dụng phương pháp Straussian GT như là một “phương pháp quy nạp có hệ thống” để nghiên cứu định tính về việc nhận diện các attack surfaces.
Quá trình phân tích bắt đầu với ba câu hỏi:
- Where are the critical entry points in a software system that are used by attackers to get in?
- What assets or components in a software system are targeted by attackers?
- How do attack surfaces emerge, and what types of mechanisms are utilized to reach the targets?
Để trả lời các câu hỏi trên, các tác giả chú trọng đến 3 theories cốt lõi: cái gì là Entry Points, Targets và Mechanisms.
- Sau khi trả lời các câu hỏi thì các tác giả trích xuất các concepts liên quan đến từng thoery để xây dựng một mô hình attack surface tổng quát.
- Trong quá trình phân tích, họ nhận thấy có thể chia các concepts này ra làm bốn nhóm chính: source code (Code), chương trình có thể thực thi của code (Program), hệ thống (System), và môi trường mạng (Network).
- Sau đó, họ nhận diện các attack surfaces cho từng danh mục và đem đi so sánh với những attack surfaces được đề xuất trong các bài báo.
Methodology
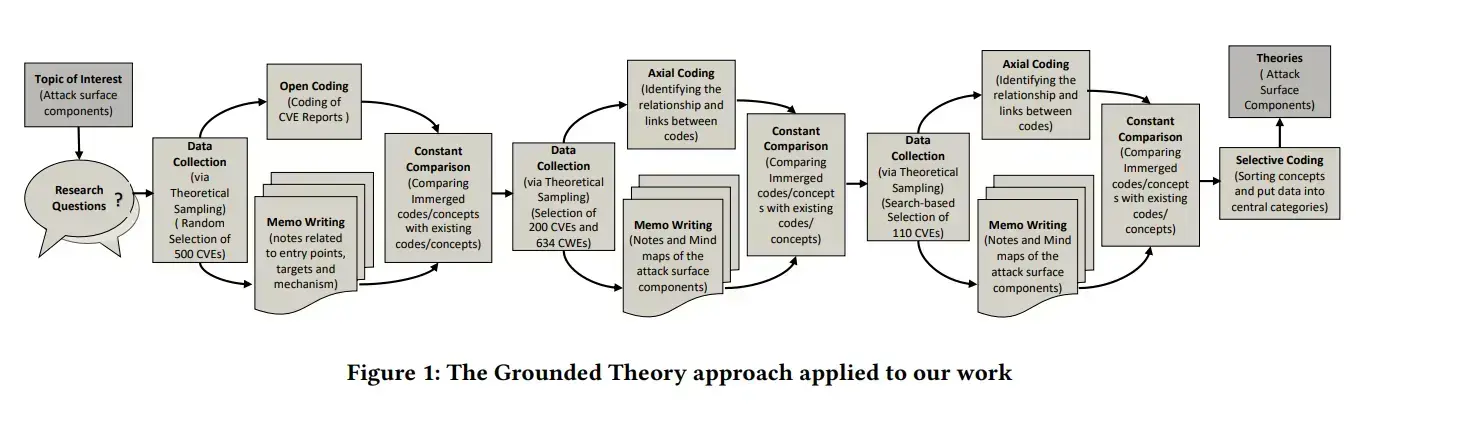
Data Collection
Theoretical Sampling
Là quá trình thu thập dữ liệu dựa trên các concepts được trích xuất từ dữ liệu.
Trong quá trình này, dữ liệu không được thu thập hết một lần ngay từ ban đầu. Có thể nói, việc thu thập dữ liệu và phân tích là một chu trình tuần hoàn. Các concepts được nhận diện trong từng chu trình sẽ dẫn đến nhiều dữ liệu được thu thập hơn. Quá trình này sẽ lặp đi lặp lại đến khi nào có sự bão hòa xảy ra.
Data Sources
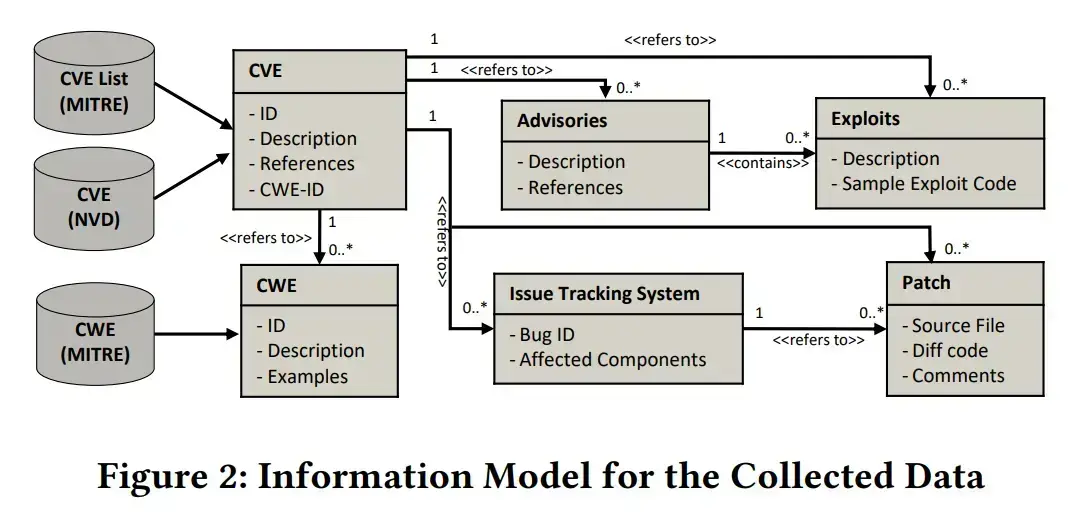
Các tác giả thu thập các thông tin về lỗ hổng dựa trên CWE và CVE.
Bởi vì CVE thường không chứa đủ các thông tin để nhận diện các attack surfaces nên họ cần phải xem xét thêm nhiều nguồn thông tin nữa. Issue tracking system (GitHub Issues là một ví dụ) là một trong số những nguồn thông tin đó.
Ngoài ra, họ còn xem xét thêm mã nguồn để nhận diện các cách vá lỗ hổng. Cụ thể, họ tập hợp các commits với message có chứa nội dung để cập một cách trực tiếp đến các bug ID ở trong các issue tracking systems hoặc trực tiếp tham chiếu đến CVE có liên quan.
Hơn thế nữa, họ còn thu thập các thông tin đến từ các URL references của CVE. Các references này thường là các vulnerability reports, advisories và exploit information.
Data Collection Process
Có ba giai đoạn:
- Giai đoạn đầu tiên: các tác giả thu thập ngẫu nhiên 100 lỗ hổng mỗi năm từ 2016 đến năm 2020 (tổng cộng 500 lỗ hổng) và các thuộc tính của chúng. Một số lỗ hổng trong CVE chỉ có mô tả chứ không có code hay advisories nên việc thông tin mà họ thu thập được khá giới hạn.
- Giai đoạn thứ hai: chọn ngẫu nhiên 200 CVEs từ 2016 đến 2020 và bỏ qua một số mảng mà theo lý thuyết là bị bão hòa trong giai đoạn đầu tiên. Họ nhận thấy rằng các CVEs thu thập được ở trong giai đoạn đầu phủ rất ít nhánh của CWE (chỉ có 70 CWE ID). Vì thế, họ còn thu thập thêm dữ liệu từ Introduced During Design và Introduced During Implementation của CWE. Ở trong giai đoạn này, các tác giả định nghĩa được các thành phần có thể có của Entry Points, Target hoặc Mechanisms.
- Giai đoạn thứ ba: họ thực hiện tìm kiếm các CVEs dựa trên từ khóa.
Open Coding
Là quá trình phân tích dữ liệu đã được thu thập cho từng lỗ hổng và chú thích chúng với các “codes” (hay còn được gọi là concepts). Cụ thể hơn, code là một cụm từ tổng hợp các ý chính. Các ý chính được gạch dưới bằng màu đỏ.
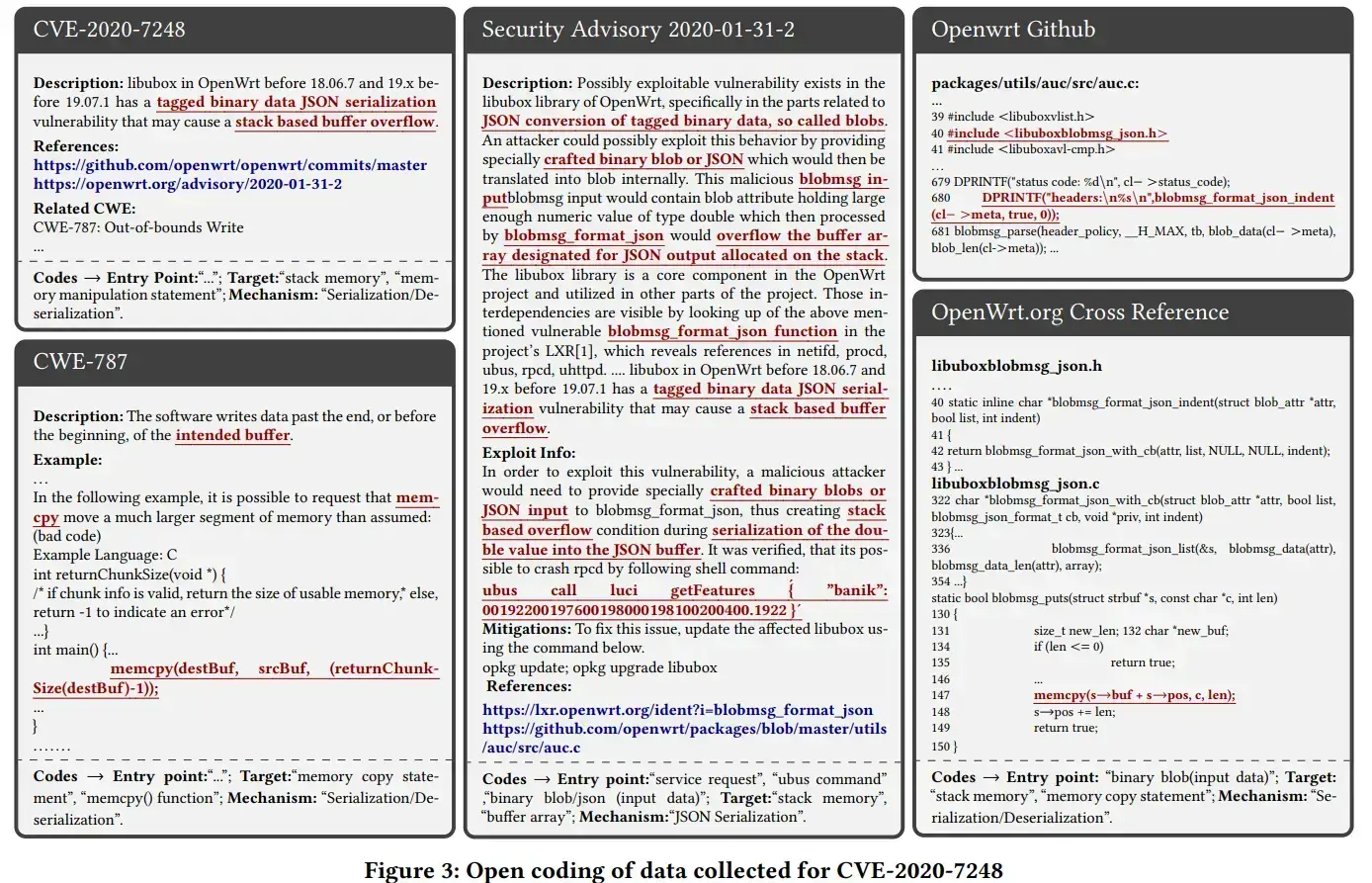
Constant Comparisions
Các tác giả so sánh các concepts/danh mục đã có với các vulnerability reports để cải tiến các danh mục và cách diễn giải dữ liệu. Mục tiêu cuối cùng của open coding và constant comparision là để nhận diện các concepts cốt lõi và các danh mục liên quan đến attack surface.
Memoing
Là các ghi chú, sơ đồ hoặc phác thảo giúp các nhà nghiên cứu mô tả ý tưởng sơ khai của họ về các tính chất và các mối quan hệ về khái niệm giữa các danh mục.
Axial Coding
Phân loại các codes dựa trên các mối quan hệ của chúng thành những concepts ở mức cao hơn.
Selective Coding
Sắp xếp các concepts đã được định nghĩa và liên kết chúng với các nhánh trung tâm, cụ thể là Program (P), Code (C), System (S) và Network (N). Trong quá trình này, các tác giả tích hợp các concepts đã được định nghĩa và cấu trúc chúng thành các mức trừu tượng cao hơn (các theories) nếu cần thiết.
Discussion
Cách tiếp cận của các tác giả có thể được dùng để nhận diện các attack surfaces của nhiều loại hệ thống khác nhau và có thể được sử dụng trong các loại phân tích phần mềm khác. Chẳng hạn như ở trong giai đoạn requirement/design, model này có thể hỗ trợ threat modeling và nhận diện được các abuse case của các entry points. Lập trình viên cũng có thể sử dụng nó trong các buổi security code reviews để nhận diện các entry points và critical parts của code cũng như là để verify sự tồn tại của các cơ chế bảo mật giúp bảo vệ những critical parts đó.
Verifiability and Threats to Validity
Trong quá trình GT, các tác giả sử dụng triangulation concept để nâng cao hiệu lực của quy trình:
- Data triangulation: ngoài CWE và CVE, các tác giả còn xem xét thêm các dữ liệu có liên quan: mô tả lỗ hổng của product advisory, các bản vá (source code) và exploint information.
- Investigator triangulation: ba tác giả làm việc với nhau để thực hiện các bước của GT. Trong khoảng thời gian một năm, các tác giả thường gặp nhau mỗi tuần, thảo luận, peer-reviewed để hoàn thiện code, memos và các concepts.
Các hạn chế:
- Hạn chế chính của nghiên cứu là việc thẩm định quá trình GT khá thách thức. Các tác giả giảm thiểu vấn đề này một phần nào đó bằng cách sử dụng literature như là nguồn thẩm định. Cụ thể hơn, họ tiến hành một systematic literature review để tìm ra mức độ mà các nghiên cứu trước đó fit với các findings của model.
- Ngoài ra, quá trình GT còn chứa nhiều quá trình phân tích thủ công và các quá trình này có khuynh hướng thiên kiến. Để giảm thiểu vấn đề này, các tác giả sử dụng investigator triangulation.
- Một hạn chế khác là các attack surfaces này chỉ đến từ các lỗ hổng trong khoảng thời gian 2016-2020. Cách giảm thiểu của các tác giả là sử dụng thêm các CWEs mà không phụ thuộc thời gian như là một nguồn dữ liệu bổ sung.